
Creating a database schema
Introduction
A Torque database schema consists of one or more XML files
describing the structure of the databases.
The files which are considered by the generator can be configured
by the sourceIncludes and sourceExcludes settings of the
maven plugin or ant task. By default, all files are considered
ending with the suffix schema.xml.
All schema files should comply either to database-5-0-strict.xsd or to database-5-0.xsd. The difference between the strict schema and the normal schema is that in the strict schema, additional naming restrictions are made which are aimed at better interoperability between databases.
It is recommended to ensure schema compliance by adding xsd information into the root database element, e.g.
<database
xmlns="http://db.apache.org/torque/5.0/templates/database"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://db.apache.org/torque/5.0/templates/database
http://db.apache.org/torque/torque-5.0/documentation/orm-reference/database-5-0-strict.xsd"
...
or
<database
xmlns="http://db.apache.org/torque/5.0/templates/database"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://db.apache.org/torque/5.0/templates/database
http://db.apache.org/torque/torque-5.0/documentation/orm-reference/database-5-0.xsd"
...
A reference of the Torque schema can be found below.
Example schema file
For an example schema file containing most of the discussed features, look at the bookstore-schema.xml from the test project.
Organisation of the schema files
A single database can consist of one or more schema files.
For small database definitions, it is best to use one schema file
per database.
For complicated database definitions, it can be better to use
more than one schema files.
To have foreign key references between tables in different files,
other schema files can either be included using the
include-schema element,
or they can be referenced using the external-schema
element.
The difference between included and referenced schemata is that
included schema are considered under torque's control, whereas
tables and views defined in an external schema file can be
referenced, but are not under torque's control.
In practice that means that an included schema can have
foreign key relations between all tables in all files,
and the ddl generation generates create (and possibly drop)
commands for all tables.
With referenced schema files, relations from the
referenced schema to the main schema are forbidden,
and the ddl generation only generates create (and/or drop)
commands for tables in the main schema, not the external schema.
With both included and referenced schema files,
care should be taken that the imported/included files
are not read on their own by the maven plugin or ant tasks.
For example, in the test project, the files included-schema.xml and ext-schema.xml are included respectively referenced by the test-schema.xml. In the configuration of the torque-maven-plugin in the pom, these files are excluded as source files in order to read them only via the include-schema/external-schema element and not as schema files of their own.
More than one database
Torque can access multiple databases with different structure and even different database vendors from within one Torque instance. Basically this means that Torque's inbuilt connection handling can handle more than one database connection pool.
There are three different scenarios for multiple databases, with different levels of support from Torque:
- Each table has a unique name; different tables belong to different databases. This situation is fully supported by the Torque runtime. If the generated peer classes (generated by the torque generator using the torque templates) are used, the different databases are handled automatically in the standard cases because each table has a default database to which it belongs.
- Some or all table names are not unique (there are tables with the same name in different databases), and the tables with the same name have the same structure (same column names and data types etc). This situation is also fully supported by the Torque runtime. However, the generated peer classes are not generated for this situation; meaning that by default, a connection for querying and saving is always opened to the default database for the given table name. This means you will either need to pass the correct database handle name for querying and saving, or not use the connection handling provided by the peer classes.
- Some or all table names are not unique (there are tables with the same name in different databases), and some of the tables with the same name have a different structure than other tables with the same name. This situation is not recommended, it is unclear to which extent it is supported.
Databases with the same structure
If your databases have the same structure, define the schema and generate the classes as if it were only one database. Accessing different databases using the generated classes is covered later in this documentation.
Databases with different structures
On schema creation time, make sure that the different databases are defined in different schema files. Also make sure that the different databases have different name attributes in the database element. Then, define different database handles using the database names from the schema files. Torque will then use the database handle with the key equal to the database element's name attribute for each table.
It is recommended to generate the classes for the different databases into different packages to keep them apart. To achieve this, the corresponding classes must be generated in different generator runs with different package settings.
Using database Schema names
It is possible to qualify table names with schema names (as in ${schema}.${table}) at generate time. To do this, use the fully qualified table name as name attribute in the <table> element of your schema.xml. For example, to use the schema "bookstore" for the table "book", use the following table definition:
...
<table name="bookstore.book" description="Book table">
...
If the standard options are used, the resulting java class name will ignore the leading database name (e.g. the class will be named Book for the example above). If you want to retain the schema names in the java names, (i.e. the resulting java class should be named "BookstoreBook"), you can either use the javaName attribute of the table definition:
...
<table name="bookstore.book" javaName="BookstoreBook" description="Book table">
...
or you can set the generation option
torque.om.retainSchemaNamesInJavaName to true.
If you use a sequence to autogenerate ids, the sequence will be generated in the same schema as the table.
In some databases (hsqldb, postgresql, mssql), a schema exists independly of other database objects (user or database). In these databases, a "create schema" (but no "drop schema") command(s) are created automatically in the ddl-sql script if qualified names are used as table names.
Creating a schema from an existing database
Torque can create a starting point for a schema file from an existing database. For doing this, Torque uses the JDBC metainformation provided by the database driver. Not all information about the schema can be collected from JDBC metainformation, so this can only serve as a starting point.
See the information about running the Torque generator on how to generate a schema file from an existing database.
Schema Reference
The database element
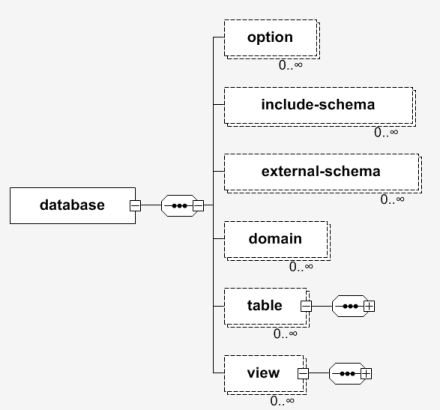
Each schema file contains one database element as root element.
The database element must have a name attribute,
which defines the default handle by which the database can be accessed.
For example, in the test project, most databases have the name
bookstore, so by default they are accessed by the
bookstore configuration settings.
A database can also define whether by default primitive or object types
are used (via the defaultJavaType attribute),
or which is the default id method to use to generate primary keys
(via the defaultIdMethod attribute).
For more information and possible value ranges, see also the xsd
database-5-0.xsd.
The database element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| include-schema | see Organisation of the schema files | 0 or more times |
| external-schema | see Organisation of the schema files | 0 or more times |
| table | see Tables | 0 or more times |
| view | see Views | 0 or more times |
| domain | definition of common data types, see Domains | 0 or more times |
The database element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The default handle by which the database can be accessed | |
| defaultJavaType | Whether by default primitive or object types are used. Permitted values are object or primitive | primitive |
| defaultIdMethod | The default id method to use to generate primary keys. Permitted values are native, idbroker and none. |
Tables
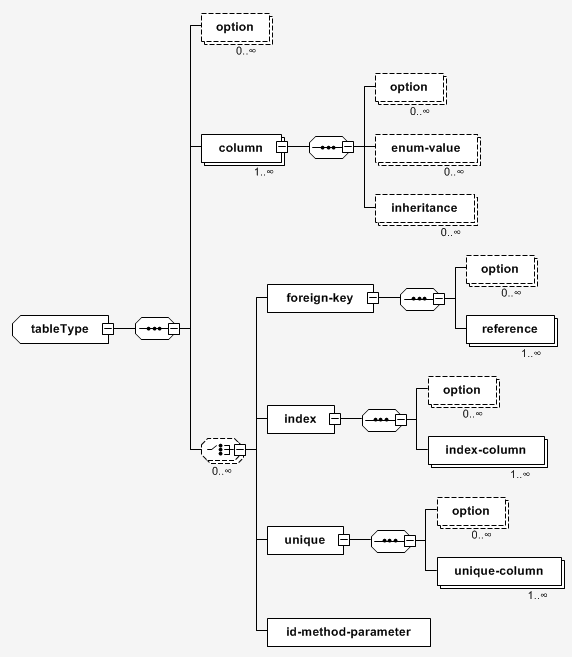
Tables are defined by the table element and have the tableType XSD type depicted in the image above. All tables must have a name and should have at least some columns. It is recommended that each table has a primary key (see below for reasons). Torque supports composite primary keys; to create one, simply set the primary-key attribute to true in more than one column of the same table.
Torque can auto-generate numeric primary keys using either the native database mechanism (idMethod="native", recommended) or a method involving an extra table (idMethod="idbroker"). For defining primary keys manually, use idMethod="none".
Foreign key relations between tables can be defined using the foreign-key element. Foreign keys can consist of one or more columns, simply add a reference elements for each column in the foreign key.
Indexes on the table can be set using the index element. Indexes can also consist of one or more columns. "Normal" indexes are not unique, use the unique element for defining unique constraints.
The table element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | Currently used only for MySQL. See the supported database page for details. | 0 or more times |
| column | see Columns | 1 or more times |
| foreign-key | see Foreign Keys | 0 or more times |
| index | see Index | 0 or more times |
| unique | see Unique | 0 or more times |
| id-method-parameter | The name of the sequence, if a sequence is used to generate the primary key. See ID Method Parameters | 0 or more times |
The table element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the table | |
| description | A description of the table. | |
| idMethod | The id method to use to generate primary keys for this table. Permitted values are native, idbroker and none. | The value of the defaultIdMethod attribute in the database element |
| skipSql | Whether to skip generation of DDL SQL(CREATE TABLE...) for this table. | false |
| javaName | The base name of the java classes representing the table | autogenerated from the name attribute |
| interface | The interface which the generated data object class for this table should implement | |
| peerInterface | The interface which the generated peer class for this table should implement | |
| baseClass | The class from which the generated data object class for this table should inherit | |
| basePeer | The class from which the generated peer class for this table should inherit | |
| abstract | Whether the generated data object class should be an abstract class | false |
Columns
The column element defines a column in a table. Each column must have a name and a type.
There are some column names which you can not use in Torque although your database would support them. These are any column name that contains characters that are not in Java's variable identifier character set. The reason is that column names are used as variable names in the OM Peer classes and these columns will cause the Torque generated code to not compile.
Note however, that SQL92 standard and up uses the same identifier characters as Java for non-delimited columns. So this should only apply to columns defined by the SQL standard as delimited columns, i.e. columns referred to surrounded by double quotes. Delimited column are considered to be case sensitive and/or contain non-standard characters. However, most good cross DB server designs should avoid these special types of column since some servers don't support delimited columns.
In addition, there are two column names that are handled slighly differently in the OM Peer classes. This is so they will not produce constants twice in the generated code. The following column names (case is ignored) will have an "_" prefixed in front of them in the Peer classes:
- TABLE_NAME => _TABLE_NAME
- DATABASE_NAME => _DATABASE_NAME
Furthermore, it is recommended that you do not use words which have a defined meaning in SQL as column names. Even if you can trick your database into using them, it is not sure whether Torque can do the same. And besides, even if it works for one database, if you ever decide to use another database, you may run into trouble then.
The column element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| inheritance | see Inheritance | 0 or more times |
| enum-value | see EnumValue | 0 or more times |
The column element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the column. Required. | |
| type | The SQL type of the column, also determines the java type. Required unless the domain attribute is set. Note that not every type is supported by every database. Also note that for most (but not all) data types, the javaType of the column can be automatically determined from the SQL type. Possible values are BIT, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, REAL, NUMERIC, DECIMAL, CHAR, VARCHAR, LONGVARCHAR, DATE, TIME, TIMESTAMP, BINARY, VARBINARY, LONGVARBINARY, NULL, OTHER, JAVA_OBJECT, DISTINCT, STRUCT, ARRAY, BLOB, CLOB, REF, BOOLEANINT, BOOLEANCHAR and DOUBLE. | |
| description | A description of the column. | |
| size | The SQL size of the column. Must be an integer. Does only make sense for some SQL Types. | |
| scale | The SQL scale of the column (number of digits after the comma). Must be an integer. Does only make sense for some SQL Types. | |
| default | The default value of the column. | |
| useDatabaseDefaultValue | Whether to use the database default value if a new object is saved and the attribute value is equal to the java default value. Has no effect on primitive boolean columns. | false |
| primaryKey | Whether this column is part of the primary key of the column. Allowed values are true and false. | false |
| required | Whether this column is required, i. e. it must be not-null Allowed values are true and false. | true for columns which are part of the primary key, false otherwise |
| autoIncrement | Whether the value for this column should be autogenerated. Has only effect for primary key columns. Allowed values are true and false. | true for columns which are part of the primary key, false otherwise |
| javaName | The base name for the column for generating java methods and fields. | Determined from the name attribute. |
| javaType | The java type for the java representation of the column. | For most types, determined from the type attribute. |
| domain | The domain to use for this column. | |
| inheritance | The inheritance type defined by this column, see the inheritance guide. Allowed values are single and false. | |
| enumType | If set, declares this column as an enum. The attribute value defines the enum class name and can either be unqualified, in which case the enum will be generated using the enum-value child elements, or the content can be fully qualified, in which case the enum must be hand-written, and needs to contain the methods getValue(), which returns the SQL value of the enum instance, and the static method getByValue(${javaType} sqlValue), which returns the enum instance corresponding to the sqlValue. | false |
| protected | If true, the generated java setters and getters for this property will be protected rather than public. Allowed values are true and false. | false |
| version | If true, this column is used as a version number for optimistic locking. I.e. for updates, Torque will check that the version number in the database is equal to the version number of the supplied object and it will automatically increase the version number of the updated row. Setting version to true will only work for numeric columns and will produce code that does not compile if applied to other column types. Allowed values are true and false. |
Primary keys
For every table, you should create a primary key which has no meaning in real life. The reasons for this are:
You should use a primary key at all because it creates a well-defined link between the objects in the database and the objects in memory. Often, one has to decide whether a java object in memory describes "the same" object as a certain row in the database. For example if you read an object from a database, change a field value and write it again to the database, you would usually want to update the row you read from. This is only possible if Torque can find the row in the database from which the object originated. For this, the primary key is used in relational databases. If two java objects have the same primary key, they describe "the same thing" and refer to the same row in the database. If you do not have a primary key, there is no well-defined way to decide if two java objects describe "the same thing". You might run into not being able to update an object.
Now that we know why we want to have a primary key at all, why should it have no meaning in real life ? This can be explained best by an example. Consider a table which holds manufactured parts. Each part has an unique serial number. So it is tempting to use the serial number as a primary key. But now imagine that we have registered the wrong serial number for a certain part in the database. Remember that the primary key is used to decide "is it the same object?" So we cannot change the serial number of a specified object without making it another object.
In Torque, this problem manifests itself in that there is no easy way to change the primary key of an object; you must trick Torque into it by using Torque's internals. This should be avoided if possible. If you use a primary key which has no meaning in real life, you do not run into that trouble.
Foreign keys
A foreign-key element defines a SQL foreign-key relation between two tables. The columns which constitute the foreign key relation are added as reference elements.
The foreign-key element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| reference | see Reference | 1 or more times |
The foreign-key element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the foreign key relation. | |
| foreignTable | The name of the foreign table. Must be a table name known in this schema. Required. | |
| onDelete | The action to be executed by the database when the referenced entry is deleted. Allowed values are cascade, setnull or restrict. | |
| onUpdate | The action to be executed by the database when the referenced entry is updated. Allowed values are cascade, setnull or restrict. |
Reference
A reference defines a link between local and foreign column for a foreign-key element.
The reference element can contain no child elements. It can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| foreign | The SQL name of the column in the foreign table. The column name must be known in the Torque schema. Required. | |
| local | The SQL name of the column in the local table. The column name must be known in the Torque schema. Required. |
EnumValue
An enum-value element defines one possible value of a column.
The enum-value element can contain the following attributes:
| attribute | description | default value |
|---|---|---|
| value | The SQL value of the enum. | |
| javaName | The name of the enum key. | computed from the value attribute |
| description | A description of the enum value |
Index
An index element defines a SQL index on a table. The columns which constitute the index are added as index-column elements.
The index element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| index-column | see Index column | 1 or more times |
The index element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the index. |
Index Column
A index-column defines a column which is part of an index.
The index-column element can contain no child elements. It can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the column which is part of the index. The column name must be known in the Torque schema. Required. |
Unique
An unique element defines a SQL unique index on a table. The columns which constitute the unique index are added as unique-column elements.
The unique element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| unique-column | see Unique column | 1 or more times |
The unique element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the unique index. |
Unique Column
A unique-column defines a column which is part of an unique index.
The unique-column element can contain no child elements. It can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the column which is part of the unique index. The column name must be known in the Torque schema. Required. |
Id method parameters
A id-method-parameter is currently only used to define the name of a sequence if th database uses a sequence for generating primary keys for a table.
The id-method-parameter element can contain no child elements. It can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | Currently not used by Torque. | |
| value | The SQL name of the sequence. |
Inheritance
A inheritance element defines the usage of a column with respect to inheritance. See the inheritance guide for details.
The id-method-parameter element can contain no child elements. It can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| key | A value found in the column marked as the inheritance key column. | |
| class | The class name for the object that will inherit the record values | |
| extends | The class that the inheritor class will extend |
Views
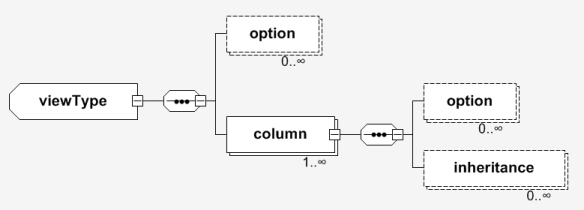
Views behave much as tables, except that they cannot be written to. and that they usually reference data from other tables.
A view definition must contain the column names and types.
To let Torque create the sql for the view, you can specify a sql suffix for the view, e.g. "from book join author on book.author_id=author.author_id", and the select snippet for each column using the select attribute, e.g. "author.author_id". E.g.
<view name="BOOK_AUTHORS" sqlSuffix="from book join author on book.author_id=author.author_id">
<column name="book_id" type="INTEGER" select="book.book_id"/>
<column name="author_id" type="INTEGER" select="author.author_id"/>
<column name="book_title" type="VARCHAR" select="book.title"/>
<column name="author_name" type="VARCHAR" select="author.name"/>
</view>
This will usually work only for simple views, but is easy to read in the schema. If you cannot create the sql like this, you can also fill the attribute createSql with the sql needed to create the sql.
The view element can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| column | see View columns | 1 or more times |
The view element can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the view | |
| baseClass | The fully qualified name of class which the generated data object class extends | |
| basePeer | The fully qualified name of class which the generated peer class extends | |
| abstract | Whether the generated data object class should be abstract | false |
| javaName | The base name of the generated java classes | generated from the SQL name |
| sqlSuffix | The suffix after the select column for the view creation SQL. | |
| createSql | The SQL to create the view. | computed from the select attributes of the columns and the sqlSuffix attribute of the view |
| skipSql | Whether to skip the create statement when generating the schema creation sql | false |
| description | A description of the view |
View Columns
View columns are similar for table columns, but have a different set of attributes because views are read-only and have a different creation SQL than tables.
The column element in a view can contain the following elements:
| element | description / reference | |
|---|---|---|
| option | currently not used by the torque templates | 0 or more times |
| inheritance | see Inheritance | 0 or more times |
The column element in a view can contain the following attributes:
| attribute | description / reference | default value |
|---|---|---|
| name | The SQL name of the column | |
| type | The SQL type of the column, also determines the java type. Required unless the domain attribute is set. Note that not every type is supported by every database. Also note that for most (but not all) data types, the javaType of the column can be automatically determined from the SQL type. Possible values are BIT, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, REAL, NUMERIC, DECIMAL, CHAR, VARCHAR, LONGVARCHAR, DATE, TIME, TIMESTAMP, BINARY, VARBINARY, LONGVARBINARY, NULL, OTHER, JAVA_OBJECT, DISTINCT, STRUCT, ARRAY, BLOB, CLOB, REF, BOOLEANINT, BOOLEANCHAR and DOUBLE. | |
| description | A description of the column. | |
| size | The SQL size of the column. Must be an integer. Does only make sense for some SQL Types. | |
| scale | The SQL scale of the column (number of digits after the comma). Must be an integer. Does only make sense for some SQL Types. | |
| javaName | The base name for the column for generating java methods and fields. | Determined from the name attribute. |
| javaType | The java type for the java representation of the column. | For most types, determined from the type attribute. |
| domain | The domain to use for this column. | |
| protected | If true, the generated java setters and getters for this property will be protected rather than public. Allowed values are true and false. | false |
| select | The SQL snippet which reads the view column value. |
Domains
A domain is used to create a common type definition. A domain must have a name and a data type and can have a size, scale and default value. Once the domain is defined, it can be used as any other data type in columns.